Note
Go to the end to download the full example code or to run this example in your browser via Binder
Feature Selection¶
Four built-in feature selection strategies using the BikeSharing dataset as example.
Experiment initialization and data preparation
from piml import Experiment
exp = Experiment()
exp.data_loader(data="BikeSharing", silent=True)
exp.data_prepare(target="cnt", task_type="regression", silent=True)
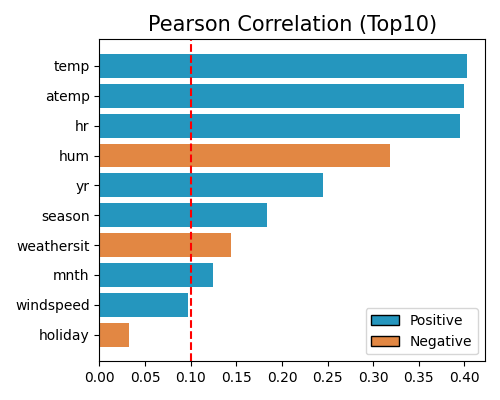
Feature selections using Pearson correlation strategy
exp.feature_select(method="cor", corr_algorithm="pearson", threshold=0.1, figsize=(5, 4))
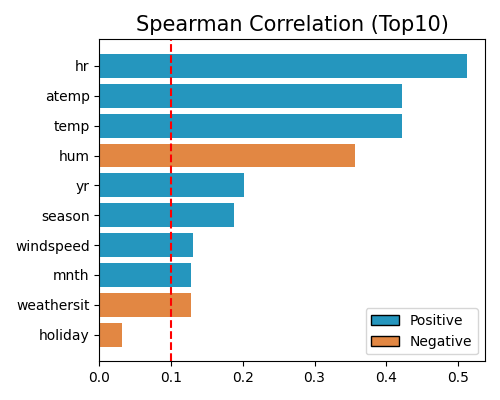
Feature selections using Spearman correlation strategy
exp.feature_select(method="cor", corr_algorithm="spearman", threshold=0.1, figsize=(5, 4))
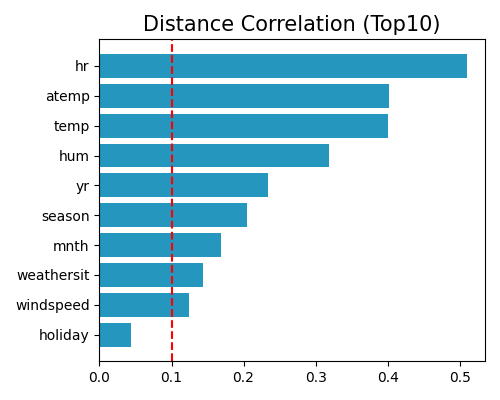
Feature selections using distance correlation strategy
exp.feature_select(method="dcor", threshold=0.1, figsize=(5, 4))
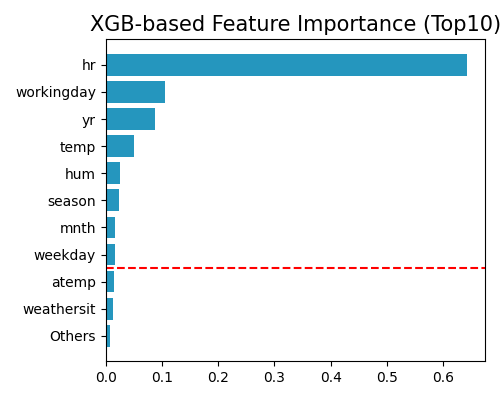
Feature selection using permutation feature importance strategy
exp.feature_select(method="pfi", threshold=0.95, figsize=(5, 4))
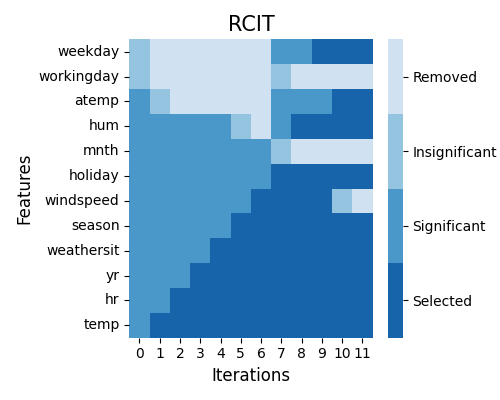
Feature selection using randomized conditional independence test strategy
exp.feature_select(method="rcit", threshold=0.001, n_forward_phase=2, kernel_size=100, figsize=(5, 4))
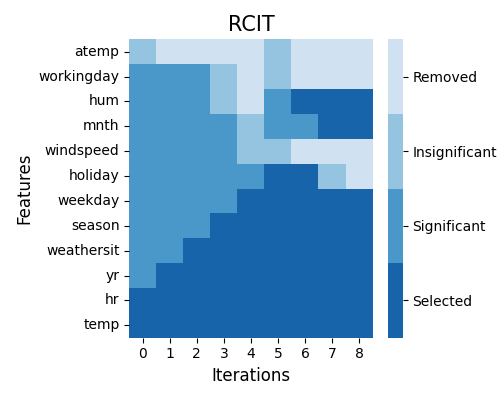
Feature selection using randomized conditional independence test strategy, where the initial Markov boundary is non-empty
exp.feature_select(method="rcit", threshold=0.001, preset=["hr", "temp"], figsize=(5, 4))
Total running time of the script: ( 1 minutes 6.865 seconds)
Estimated memory usage: 973 MB