Note
Go to the end to download the full example code or to run this example in your browser via Binder
Register PySpark Models¶
Here we show how to write a wrapper for PySpark models.
For demonstration, we first fit a GBT model using SimuCredit data.
import os
os.environ["PYSPARK_PYTHON"] = "python"
import pandas as pd
from pyspark.ml import Pipeline
from pyspark.sql import SparkSession
from pyspark.ml.classification import GBTClassifier
from pyspark.ml.feature import VectorAssembler
data = pd.read_csv('https://github.com/SelfExplainML/PiML-Toolbox/blob/main/datasets/SimuCredit.csv?raw=true')
feature_names = ['Mortgage', 'Balance', 'Amount Past Due', 'Credit Inquiry', 'Open Trade', 'Delinquency', 'Utilization']
target_name = 'Approved'
spark = SparkSession.builder.appName("SimuCredit-Spark-Demo").getOrCreate()
spark_df = spark.createDataFrame(data)
train_data, test_data = spark_df.randomSplit([0.8, 0.2], seed=2024)
feature_assembler = VectorAssembler(inputCols=feature_names, outputCol="features")
gbt = GBTClassifier(labelCol=target_name, seed=2024)
pipeline = Pipeline(stages=[feature_assembler, gbt])
model = pipeline.fit(train_data)
Next, we define the wrapper functions of predict and predict_proba.
def predict_func(X):
sdf = spark.createDataFrame(pd.DataFrame(X, columns=feature_names))
pred = model.transform(sdf).select('prediction').toPandas().values.astype(float).ravel()
return pred
def predict_proba_func(X):
sdf = spark.createDataFrame(pd.DataFrame(X, columns=feature_names))
predictions = model.transform(sdf).select('probability').toPandas()
proba = predictions.explode('probability').values.reshape((-1, 2)).astype(float)
return proba
Register the fitted model into PiML (please make sure the datasets of different pipelines are the same)
from piml import Experiment
exp = Experiment(highcode_only=True)
pipeline = exp.make_pipeline(predict_func=predict_func,
predict_proba_func=predict_proba_func,
task_type="classification",
train_x=train_data.select(feature_names).toPandas().values,
train_y=train_data.select(target_name).toPandas().values,
test_x=test_data.select(feature_names).toPandas().values,
test_y=test_data.select(target_name).toPandas().values,
feature_names=feature_names,
target_name=target_name)
exp.register(pipeline, "Spark-GBT")
Check model performance
exp.model_diagnose(model="Spark-GBT", show="accuracy_table")
ACC AUC F1 LogLoss Brier
Train 0.7046 0.7737 0.7253 0.5658 0.1923
Test 0.6991 0.7552 0.7243 0.5846 0.1996
Gap -0.0055 -0.0185 -0.0010 0.0188 0.0073
Run validataion tests
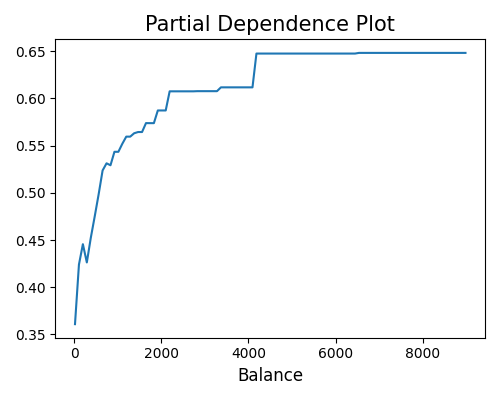
exp.model_explain(model="Spark-GBT", show="pdp", uni_feature="Balance", sample_size=1000, figsize=(5, 4))
Total running time of the script: (13 minutes 10.683 seconds)