Note
Go to the end to download the full example code or to run this example in your browser via Binder
GLM Logistic Regression (Taiwan Credit)¶
Experiment initialization and data preparation
from piml import Experiment
from piml.models import GLMClassifier
exp = Experiment()
exp.data_loader(data="TaiwanCredit", silent=True)
exp.data_summary(feature_exclude=["LIMIT_BAL", "SEX", "EDUCATION", "MARRIAGE", "AGE"], silent=True)
exp.data_prepare(target="FlagDefault", task_type="classification", silent=True)
Train Model
exp.model_train(model=GLMClassifier(), name="GLM")
Evaluate predictive performance
exp.model_diagnose(model="GLM", show='accuracy_table')
ACC AUC F1 LogLoss Brier
Train 0.8083 0.7375 0.3745 0.4585 0.1431
Test 0.8150 0.7356 0.3764 0.4458 0.1385
Gap 0.0067 -0.0019 0.0019 -0.0127 -0.0046
Regression coefficient plot for numerical features
exp.model_interpret(model="GLM", show="glm_coef_plot", figsize=(5, 4))
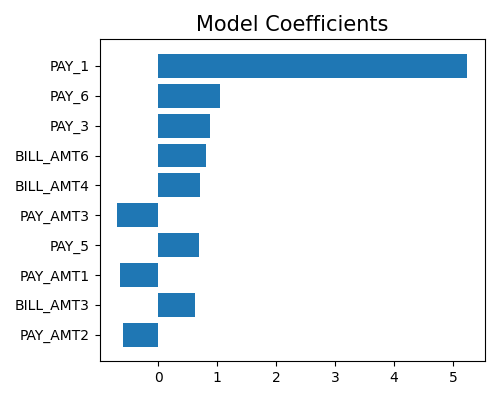
Regression coefficient table for all features
exp.model_interpret(model="GLM", show="glm_coef_table")
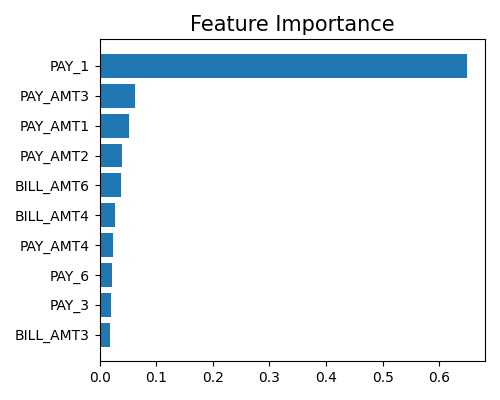
Feature importance plot
exp.model_interpret(model="GLM", show="global_fi", figsize=(5, 4))
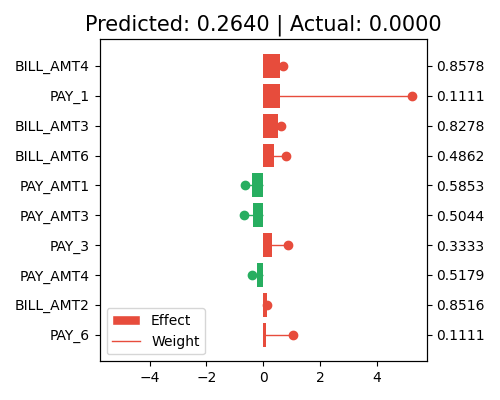
Local interpretation without centering
exp.model_interpret(model="GLM", show="local_fi", sample_id=0, centered=False, original_scale=False, figsize=(5, 4))
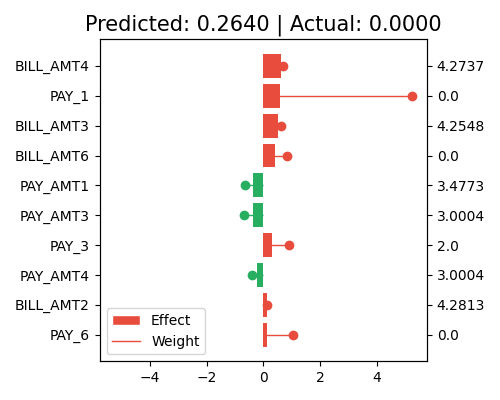
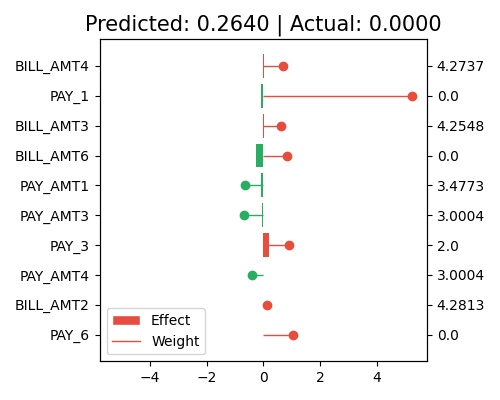
Local interpretation with original scale of x
exp.model_interpret(model="GLM", show="local_fi", sample_id=0, centered=False, original_scale=True, figsize=(5, 4))
Local interpretation with centering and original scale of x
exp.model_interpret(model="GLM", show="local_fi", sample_id=0, centered=True, original_scale=True, figsize=(5, 4))
Total running time of the script: ( 0 minutes 57.648 seconds)
Estimated memory usage: 34 MB