Note
Go to the end to download the full example code or to run this example in your browser via Binder
Segmented Diagnose (Classification)¶
Experiment initialization and data preparation
from piml import Experiment
from piml.models import XGB2Classifier
exp = Experiment()
exp.data_loader("SimuCredit", silent=True)
exp.data_summary(feature_exclude=["Race", "Gender"], silent=True)
exp.data_prepare(target="Approved", task_type="classification", silent=True)
Train Model
exp.model_train(XGB2Classifier(), name="XGB2")
Summary of all segments (top 10 with the worst performance)
result = exp.segmented_diagnose(model="XGB2", show="segment_table", segment_method="auto", return_data=True)
result.data.head(10)
<pandas.io.formats.style.Styler object at 0x0000020332A6B820>
Summary of all segments of a given feature (top 10 with the worst performance)
result = exp.segmented_diagnose(model="XGB2", show="segment_table", segment_method="auto",
segment_feature="Balance", return_data=True)
result.data
<pandas.io.formats.style.Styler object at 0x00000203172F50D0>
Accuracy talbe of the samples in that segment
exp.segmented_diagnose(model="XGB2", show="accuracy_table",
segment_id=0, segment_method="auto", segment_feature="Balance")
ACC AUC F1 LogLoss Brier
Train 0.7563 0.8512 0.7622 0.4899 0.1604
Test 0.5397 0.5777 0.5538 0.7566 0.2760
Gap -0.2166 -0.2735 -0.2084 0.2667 0.1156
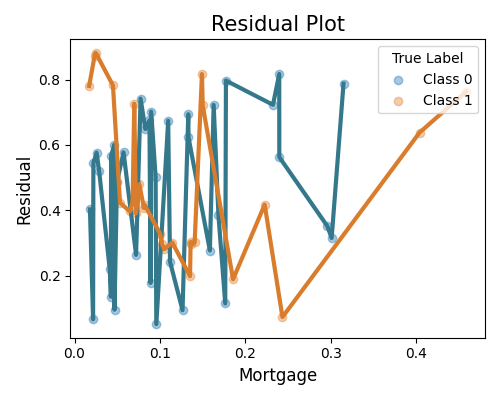
Residual analysis of the samples in that segment
exp.segmented_diagnose(model="XGB2", show="accuracy_residual",
segment_id=0, segment_method="auto", segment_feature="Balance",
show_feature="Mortgage", figsize=(5, 4))
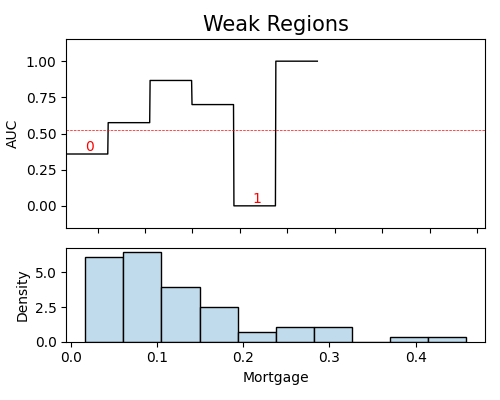
Weakspot analysis of the samples in that segment
exp.segmented_diagnose(model="XGB2", show="weakspot",
segment_id=0, segment_method="auto", segment_feature="Balance",
slice_features=["Mortgage"], metric="AUC", figsize=(5, 4))
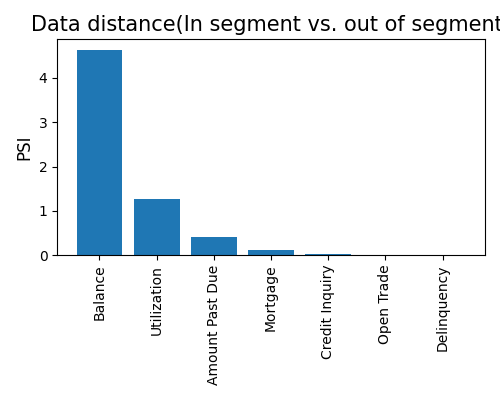
Distributional distance comparison between the specificed segment and the remaining (feature-by-feature)
res = exp.segmented_diagnose(model="XGB2", show="distribution_shift",
segment_id=0, segment_method="auto", segment_feature="Balance",
figsize=(5, 4), return_data=True)
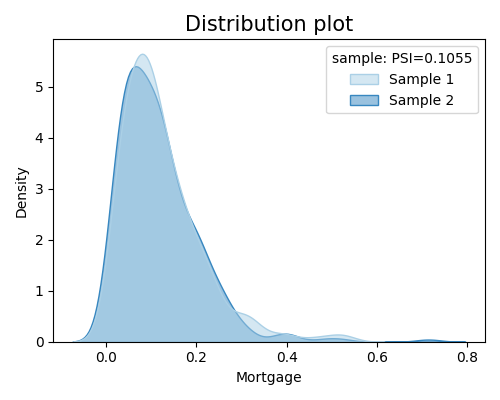
Distributional distance comparison between the specificed segment and the remaining (density of one selected feature)
res = exp.segmented_diagnose(model="XGB2", show="distribution_shift",
segment_id=0, segment_method="auto", segment_feature="Balance",
show_feature="Mortgage", figsize=(5, 4), return_data=True)
Total running time of the script: ( 0 minutes 51.680 seconds)
Estimated memory usage: 41 MB