3.3. Register Arbitrary Models¶
In additon to sklearn and H2O models, we also support to test models in arbitrary format, as long as it can provide a predict function.
3.3.1. Train and Register Models¶
Below, we simulate a simple binary classification dataset and then fit a GLM model using statsmodels package. As this model is neither sklearn nor H2O models, we use it here to demonstrate how to register arbitrary machine learning models.
import numpy as np
import statsmodels.api as sm
x = np.random.uniform(-1, 1, size=(1000, 2))
y = (np.sum(x, axis=1) + np.random.normal(0, 0.1, size=(1000,))) > 0.0
glm_binom = sm.GLM(y, x, family=sm.families.Binomial())
glm_results = glm_binom.fit()
3.3.2. Define Wrapper Predict Functions¶
Next, we need to write a wrapper function for making predictions using the model. As this is a binary classification task, we need both predict_proba and predict functions. Both of them takes covariates X as input, which is expected to be a numpy array of size (n, p). The output of predict_proba should be a numpy array of size (n, 2), which is the predicted probability of each sample. The predict function outputs the final predicted label, which is of shape (n, ).
def predict_proba_func(X):
proba = glm_binom.predict(glm_results.params, exog=X)
return np.vstack([1 - proba, proba]).T
def predict_func(X):
proba = glm_binom.predict(glm_results.params, exog=X)
return proba > 0.5
3.3.3. Register the predict Functions¶
As the predict functions have been prepared, the next step is to call the make_pipeline function and PiML would further wrap it as a sklearn style model estimator, as shown below. Finally, the pipeline can be registered and all the tests in PiML can be used.
from piml import Experiment
exp = Experiment(highcode_only=True)
pipeline = exp.make_pipeline(predict_func=predict_func,
predict_proba_func=predict_proba_func,
task_type="classification",
train_x=x[:800],
train_y=y[:800],
test_x=x[800:],
test_y=y[800:],
feature_names=["X0", "X1"],
target_name="Y")
exp.register(pipeline, "Statsmodels-GLM")
3.3.4. Run Diagnostic Tests¶
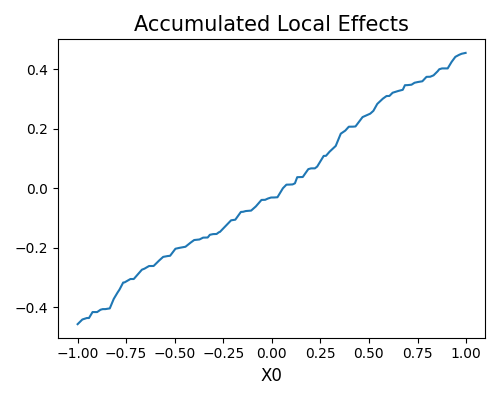
As a model is registered, then all the tests and explanation tools in PiML can be used. For example,
exp.model_explain(model="Statsmodels-GLM", show="ale", uni_feature="X0", figsize=(5, 4))