Note
Go to the end to download the full example code or to run this example in your browser via Binder
Data Quality Check¶
Data quality analysis result using the BikeSharing dataset as example
Experiment initialization and data preparation
from piml import Experiment
from piml.data.outlier_detection import (PCA, CBLOF, IsolationForest, KMeansTree,
OneClassSVM, KNN, HBOS, ECOD)
exp = Experiment()
exp.data_loader(data="BikeSharing", silent=True)
exp.data_summary(feature_exclude=["yr", "mnth", "temp"], silent=True)
exp.data_prepare(target="cnt", task_type="regression", silent=True)
Data integrity check for each column
res = exp.data_quality(show='integrity_single_column_check', return_data=True)
res.data
<pandas.io.formats.style.Styler object at 0x0000022054BE01C0>
Data integrity check for duplicated samples
res = exp.data_quality(show='integrity_duplicated_samples', return_data=True)
res.data
Leakage season hr holiday weekday workingday \
[1507, 9867] False 1.0 4.0 0.0 2.0 1.0
[9822, 17336] False 1.0 5.0 0.0 0.0 0.0
[13559, 13727] True 3.0 4.0 0.0 2.0 1.0
[5598, 14639] False 3.0 4.0 0.0 5.0 1.0
[7958, 8126] False 4.0 6.0 0.0 6.0 0.0
weathersit atemp hum windspeed cnt
[1507, 9867] 1.0 0.2727 0.64 0.0000 2.0
[9822, 17336] 2.0 0.2273 0.48 0.2985 2.0
[13559, 13727] 1.0 0.6061 0.83 0.0896 6.0
[5598, 14639] 1.0 0.5606 0.88 0.0000 8.0
[7958, 8126] 1.0 0.2576 0.65 0.1045 11.0
Data integrity check for correlated features
res = exp.data_quality(show='integrity_highly_correlated_features', return_data=True)
res.data
<pandas.io.formats.style.Styler object at 0x000002205340DDC0>
Data quality check for score distribution plot
exp.data_quality(method=PCA(), show='od_score_distribution', threshold=0.999, figsize=(5, 4))
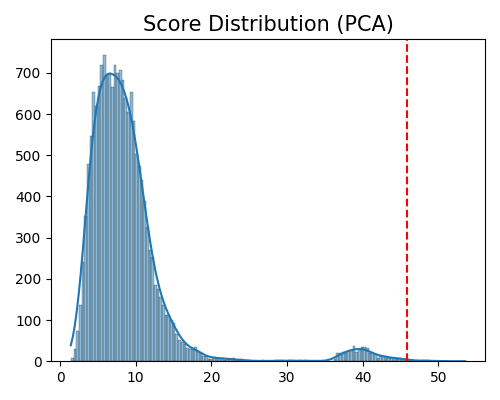
Data quality check for score distribution plot
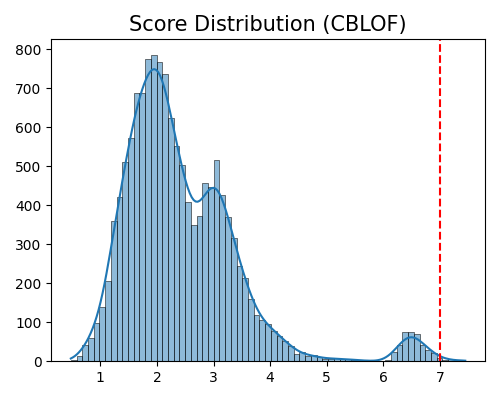
exp.data_quality(method=CBLOF(), show='od_score_distribution', threshold=0.999, figsize=(5, 4))
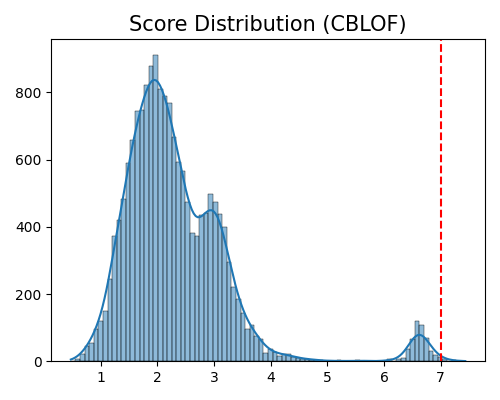
Data quality check for score distribution plot
exp.data_quality(method=IsolationForest(), show='od_score_distribution', threshold=0.999, figsize=(5, 4))
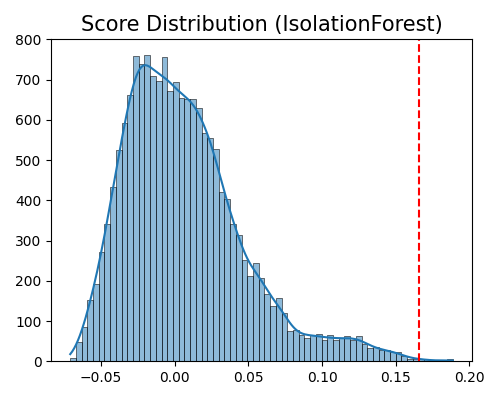
Data quality check for score distribution plot
exp.data_quality(method=KMeansTree(), show='od_score_distribution', threshold=0.999, figsize=(5, 4))
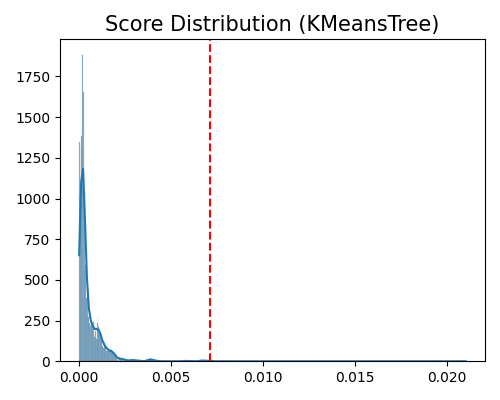
Data quality check for score distribution plot
exp.data_quality(method=KNN(), show='od_score_distribution', threshold=0.999, figsize=(5, 4))
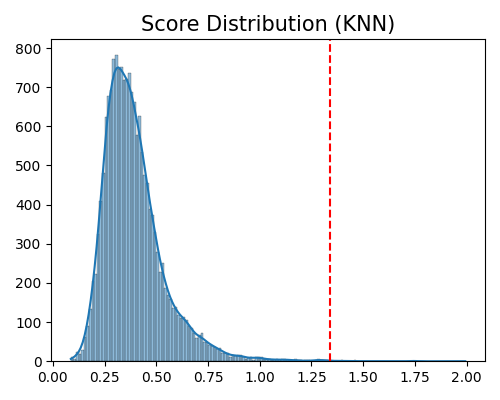
Data quality check for score distribution plot
exp.data_quality(method=HBOS(), show='od_score_distribution', threshold=0.999, figsize=(5, 4))
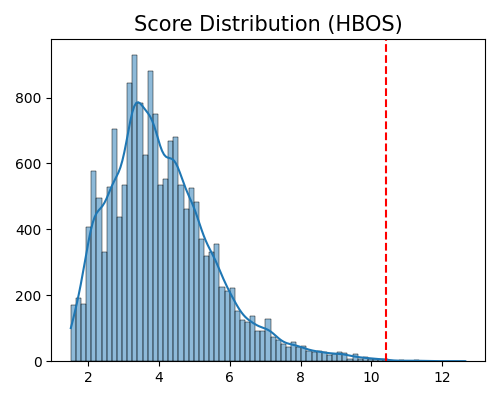
Data quality check for score distribution plot
exp.data_quality(method=ECOD(), show='od_score_distribution', threshold=0.999, figsize=(5, 4))
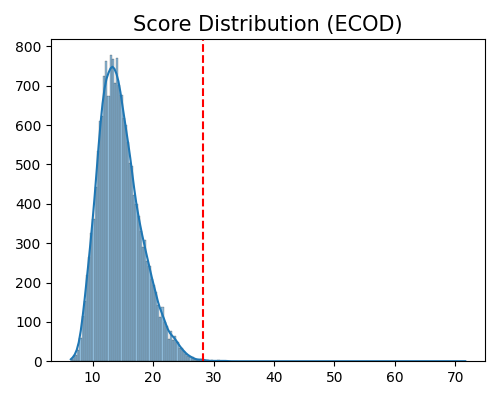
Data quality check for score distribution plot
exp.data_quality(method=OneClassSVM(), show='od_score_distribution', threshold=0.999, figsize=(5, 4))
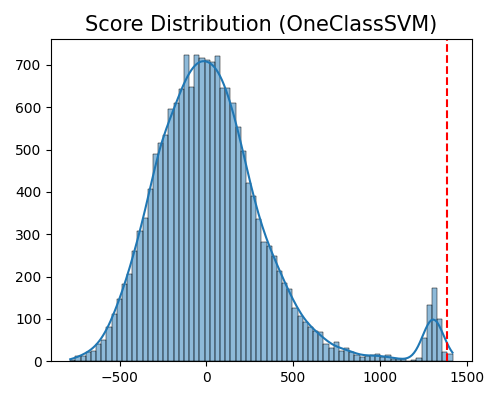
Data quality check for score distribution plot
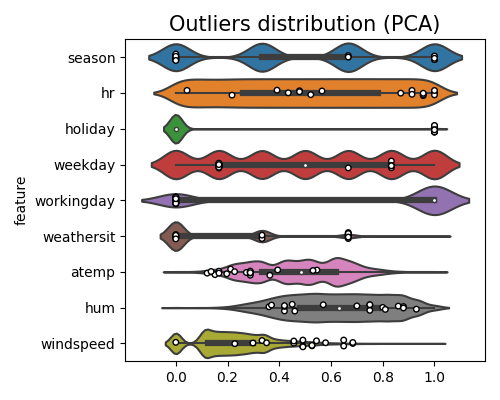
exp.data_quality(method=PCA(), show='od_marginal_outlier_distribution',
threshold=0.999, figsize=(5, 4))
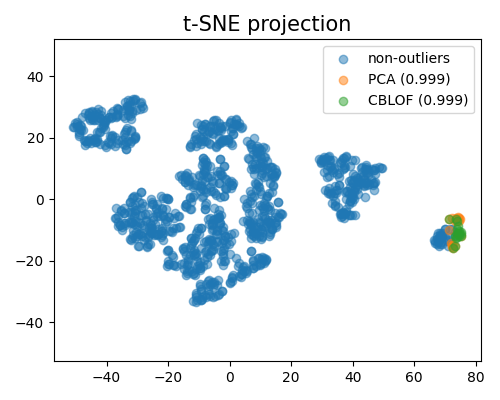
Compare different outlier detection algorithms
Select a method and threshold and apply the outlier removal (you can also specify train, test, or all data)
exp.data_quality(method=CBLOF(), show='od_score_distribution', dataset="train",
threshold=0.999, remove_outliers=True, figsize=(5, 4))
Compare the train and test data energy distance.
exp.data_quality(show='drift_test_info')
Train Size Test Size Energy Distance
0 13889 3476 0.000488
Compare the train and test marginal data drift feature-by-feature.
exp.data_quality(show='drift_test_distance', figsize=(5, 4))
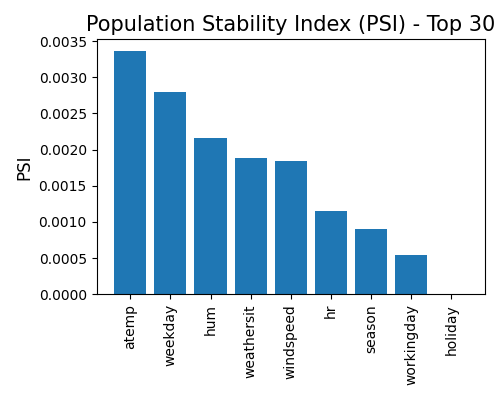
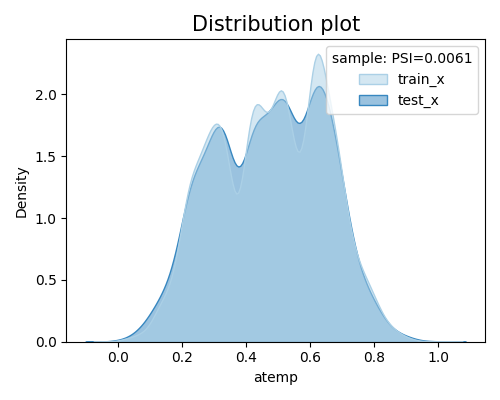
Compare the train and test marginal data drift of a given feature.
exp.data_quality(show="drift_test_distance", distance_metric="PSI", psi_buckets='quantile',
show_feature="atemp", figsize=(5, 4))
Total running time of the script: ( 2 minutes 3.914 seconds)
Estimated memory usage: 1326 MB