1. Introduction¶
PiML (read \(\pi\)-ML, /`pai·`em·`el/) is an integrated and open-access Python toolbox for interpretable machine learning model development and model diagnostics. It is designed with machine learning workflows in both low-code and high-code modes, including data pipeline, model training, model interpretation and explanation, and model diagnostics and comparison. The toolbox supports a growing list of interpretable models (e.g., GAM, GAMI-Net, XGB2) with inherent local and/or global interpretability. It also supports model-agnostic explainability tools (e.g., PFI, PDP, LIME, SHAP) and a powerful suite of model-agnostic diagnostics (e.g., weakness, uncertainty, robustness, fairness). Integration of PiML models and tests to existing MLOps platforms for quality assurance are enabled by flexible high-code APIs. Furthermore, PiML toolbox comes with a comprehensive user guide and hands-on examples, including the applications for model development and validation in banking. The project is available at https://github.com/SelfExplainML/PiML-Toolbox.
1.1. Introduction¶
Supervised machine learning has being increasingly used in domains where decision making can have significant consequences. However, the lack of interpretability of many machine learning models makes it difficult to understand and trust the model-based decisions. This leads to growing interest in interpretable machine learning and model diagnostics. There emerge algorithms and packages for model-agnostic explainability, including the inspection module (including permutation feature importance, partial dependence) in scikit-learn [Pedregosa2011] and various others, e.g., [Kokhlikyan2020], [Klaise2021], [Baniecki2021], [Li2022].
Post-hoc explainability tools are useful for black-box models, but they are known to have general pitfalls [Rudin2019], [Molnar2020]. Inherently interpretable models are suggested for machine learning model development [Yang2021a], [Yang2021b], [Sudjianto2020]. The InterpretML package [Nori2013] by Microsoft Research is such a package of promoting the use of inherently interpretable models, in particular their explainable boosting machine (EBM) based on the GA2M model [Lou2013]. One may also refer to [Sudjianto2021] for discussion about how to design inherently interpretable machine learning models.
In the meantime, model diagnostic tools become increasingly important for model validation and outcome testing. New tools and platforms are developed for model weakness detection and error analysis, e.g., [Chung2019], PyCaret package, TensorFlow model analysis, FINRA’s model validation toolkit, and Microsoft’s responsible AI toolbox. They can be used for arbitrary pre-trained models, in the same way as the post-hoc explainability tools. Such type of model diagnostics or validation is sometimes referred to as black-box testing, and there is an increasing demand of diagnostic tests for quality assurance of machine learning models.
It is our goal to design an integrated Python toolbox for interpretable machine learning, for both model development and model diagnostics. This is particularly needed for model risk management in banking, where it is a routine exercise to run model validation including evaluation of model conceptual soundness and outcome testing from various angles. An inherently interpretable machine learning model tends to be more conceptually sound, while it is subject to model diagnostics in terms of accuracy, weakness detection, fairness, uncertainty, robustness and resilience. The PiML toolbox we develop is such a unique Python tool that supports not only a growing list of interpretable models, but also an enhanced suite of multiple diagnostic tests. It has been adopted by multiple banks since its first launch on May 4, 2022.
1.2. Toolbox Design¶
PiML toolbox is designed to support machine learning workflows by both low-code interface and high-code APIs; see Figure below for the overall design.
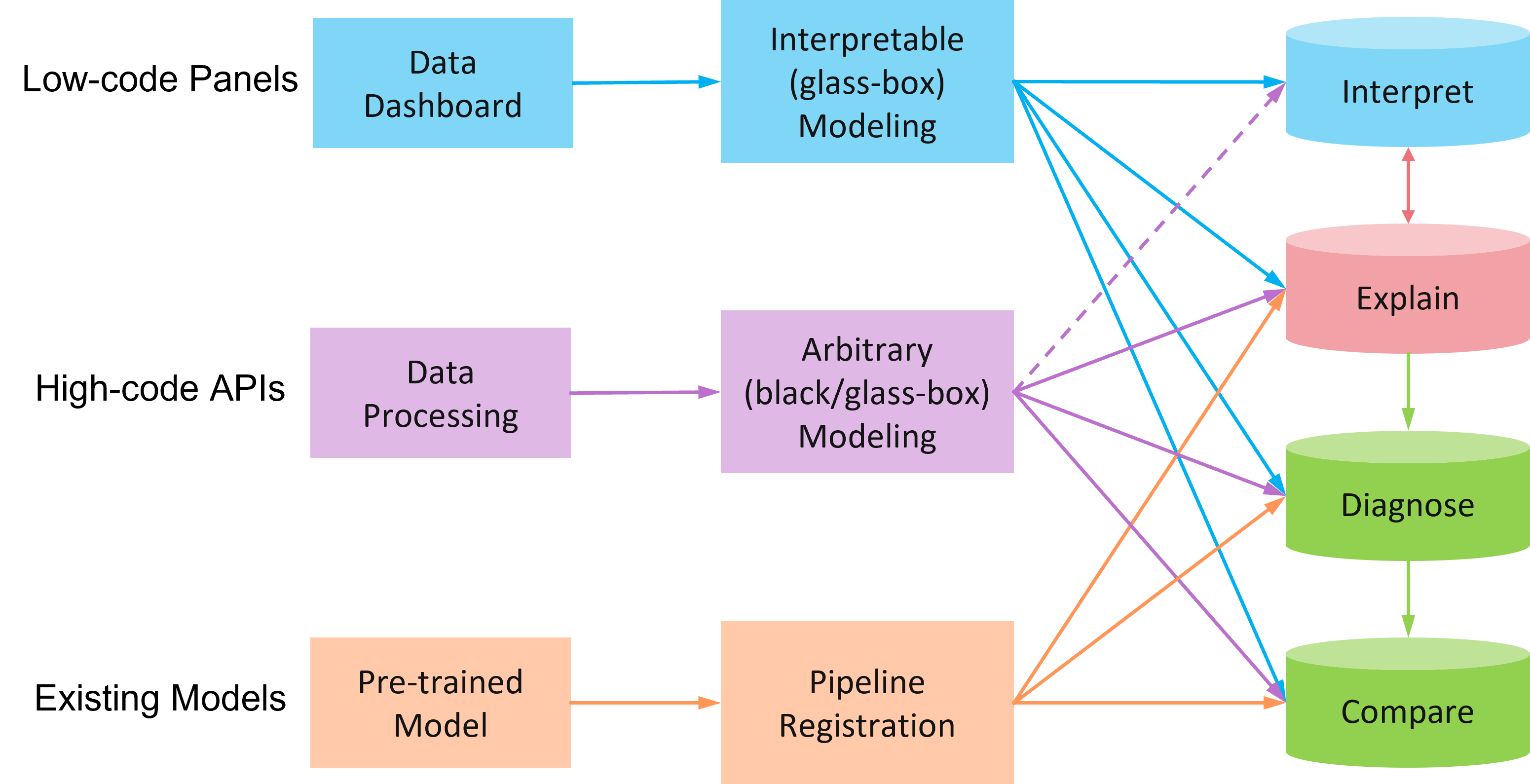
Low-code panels: interactive widgets or dashboards are developed for Jupyter notebook or Jupyter lab users. A minimum level of Python coding is required. The data pipeline consists of convenient
exp.data_load(),exp.data_summary(),exp.eda(),exp.data_quality(),exp.feature_select(),exp.data_prepare(), each calling an interactive panel with choices of parameterization and actions.High-code APIs: each low-code panel can be also executed through one or more Python functions with manually specified options and parameters. Such high-code APIs are flexible to be called both in Jupyter notebook cells and by Terminal command lines. High-code APIs usually provide more options than their default use in low-code panels. End-to-end pipeline automation can be enabled with appropriate high-code settings.
Existing models: a pre-trained model can be loaded to PiML experimentation through pipeline registration. It is mandatory to include both training and testing datasets, in order for the model to take the full advantage of PiML explanation and diagnostic capabilities. It can be an arbitrary model in supervised learning settings, including regression and binary classification.
For PiML-trained models by either low-code interface or high-code APIs, there are four follow-up actions to be executed:
model_interpret(): this unified API works only for inherently interpretable models (a.k.a., glass models) to be discussed in section_3. It provides model-specific interpretation in both global and local ways. For example, a linear model is interpreted locally through model coefficients or marginal effects, while a decision tree is interpreted locally through the tree path.model_explain(): this unified API works for arbitrary models including black-box models and glass-box models. It provides post-hoc global explainability through permutation feature importance (PFI) and partial dependence plot (PDP) throughsklearn.inspectmodule, accumulated local effects [Apley2016], and post-hoc local explainability through LIME [Ribeiro2016] and SHAP [Lundberg2017].model_diagnose(): this unified API works for arbitrary models and performs model diagnostics to be discussed in section_4. It is designed to cover standardized general-purpose tests based on model data and predictions, i.e., model-agnostic tests. There is no need to access the model internals.model_compare(): this unified API is to compare two or three models at the same time, in terms of model performance and other diagnostic aspects. By inspecting the dashboard of graphical plots, one can easily rank models under comparison.
For registered models that are not trained from PiML, they are automatically treated as black-box models, even though such a model may be inherently interpretable (e.g., linear regression model). This is due to simplification of pipeline registration, where only the model prediction method is considered. For these models, model_interpret() is not valid, while the other three unified APIs are fully functional.
Regarding PiML high-code APIs, it is worthwhile to mention that these APIs are flexible enough for integration into existing MLOps platforms. After PiML installation to MLOps backend, the high-code APIs can be called not only to train interpretable models, but also to perform arbitrary model testing for quality assurance.
1.3. Interpretable Models¶
PiML supports a growing list of inherently interpretable models. For simplicity, we only list the models and the references. The following list of interpretable models are included PiML toolbox V0.6 (latest update: Feb. 2024).
GLM: Linear/logistic regression with \(\ell_1\) and/or \(\ell_2\) regularization [Hastie2015]
GAM: Generalized additive models using B-splines [Serven2018]
Tree: Decision tree for classification and regression [Pedregosa2011]
FIGS: Fast interpretable greedy-tree sums [Tan2022]
XGB1: Extreme gradient boosted trees of depth 1, using optimal binning [Chen2015], [Guillermo2020]
XGB2: Extreme gradient boosted trees of depth 2, with purified effects [Chen2015], [Lengerich2020]
EBM: Explainable boosting machine [Lou2013], [Nori2013]
GAMI-Net: Generalized additive model with structured interactions [Yang2021b]
ReLU-DNN: Deep ReLU networks using Aletheia unwrapper and sparsification [Sudjianto2020]
1.4. Diagnostic Suite¶
PiML comes with a continuously enhanced suite of diagnostic tests for arbitrary supervised machine learning models under regression and binary classification settings. Below is a list of the supported general-purpose tests with brief descriptions.
Accuracy: popular metrics like MSE, MAE for regression tasks and ACC, AUC, Recall, Precision, F1-score for binary classification tasks.
WeakSpot: identification of weak regions with high magnitude of residuals by 1D and 2D slicing techniques.
Overfit/Underfit: identification of overfitting/underfitting regions according to train-test performance gap, also by 1D and 2D slicing techniques.
Reliability: quantification of prediction uncertainty by split conformal prediction and slicing techniques.
Robustness: evaluation of performance degradation under different sizes of covariate noise perturbation [Cui2023].
Resilience: evaluation of performance degradation under different out-of-distribution scenarios.
Fairness: disparity test, segmented analysis and model de-bias through binning and thresholding techniques.
1.5. Future Plan¶
PiML toolbox is our new initiative of integrating state-of-the-art methods in interpretable machine learning and model diagnostics. It provides convenient user interfaces and flexible APIs for easy use of model interpretation, explanation, testing and comparison. Our future plan is to continuously improve the user experience, add new interpretable models, and expand the diagnostic suite. It is also our plan to enhance PiML experimentation with tracking and reporting.