6.9. Scored Test¶
The scored test is a distinctive element of PiML diagnostic testing, specifically tailored for scenarios where the model object is absent, and only the model predictions are provided. This test necessitates solely the input features, target response data, and the corresponding model predictions.
In PiML, the scored test consists of a set of individual functions outside the Experiment workflow. These functions follow a consistent naming convention observed in other tests within the “model diagnose” module. These tests generally share a common prefix of “test”, such as “test_accuracy_table” and “test_accuracy_residual”.
6.9.1. Usage¶
The scored test covers all the tests in exp.model_diagnose, except for the robustness test. As the robustness test requires the model object to get the prediction of perturbed samples, it does not fit the requirements of the scored test. Here is a list of the supported scored tests:
test_accuracy_table: Get the accuracy result
test_accuracy_plot: Plot confusion matrix, ROC, and Recall-Precision, only support classifiers.
test_accuracy_residual: Get marginal residual plot based on a given feature.
test_weakspot: Get marginal weakspot result based on a given feature.
test_overfit: Get marginal overfit result based on a given feature.
test_reliability_table: Get empirical coverage and average bandwidth for regression or Brier Loss for classification.
test_reliability_distance: Compare data distance between reliable and unreliable samples.
test_reliability_marginal: Get marginal slicing reliability result based on a given feature.
test_reliability_perf: Get a reliability diagram, only for classifiers.
test_reliability_calibration: Get the calibrated predicted probability vs. original predicted probability, only for classifiers.
test_resilience_perf: Get resilience test results in each step.
test_resilience_distance: Compare data distance between samples in the worst region and the remaining region.
test_resilience_shift_histogram: Compare marginal distribution histogram between the worst region and remaining region.
test_resilience_shift_density: Compare marginal distribution density between the worst region and the remaining region.
All the scored tests share the same data inputs, as shown below:
x: Input data in the type of numpy array, including all train and test data
y: Target data in the type of numpy array, including all train and test data
prediction: Prediction result of model to test
prediction_proba: Prediction probability of model to test, only for classifiers
feature_names: List of feature names of input data, e.g., [‘temperature’, ‘season’]
feature_types: List of feature types of input data, e.g., [‘numerical’, ‘categorical’]
target_name: Target feature name
task_type: Task type, can be ‘regression’ or ‘classification’
train_idx: Train samples index
test_idx: Test samples index
random_state: Random seed
To simplify the input parameters for each scored test function, we can consolidate all data-related parameters into a single dictionary. Then, we can pass the data information and additional parameters to execute different tests. For example, the test_accuracy_residual test shows the residual plot against one feature of interest.
from piml.scored_test import test_accuracy_residual
result = test_accuracy_residual(**data_dict, show_feature='MedInc', figsize=(5, 4))
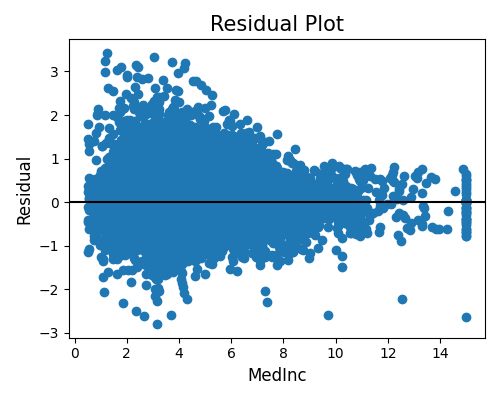
Here, we first pass the data_dict to the function. This test further requires the show_feature parameter, which is the feature of interest. Finally, the figsize parameter controls the size of the figure.